昨天我們提到的例子中,說明在蒙地卡羅方法中使用貪婪法,可能不會收斂於最佳動作的情況。並提到在 GridWorld 中,如果使用不同的設定,例如:「初始化方法不同」、「獎勵函數設計不同」...等,就會導致這樣的結果。而這些可能的結果,某種程度上限制了強化學習的應用。今天介紹的  - greedy ,就是針對貪婪法的改善。
- greedy ,就是針對貪婪法的改善。
- greedy在前言中我們提到,只要稍微修改設定,貪婪法可能會不收斂於最佳動作。事實上,我們修改的這些設定,都是導致同一個結果 —「讓最佳動作沒有被選到的機會」。因為不曾被選擇,在算法內部也不會更新該動作這些動作價值。
換句話說,只要增加選擇其他動作被選到的可能性,那麼就有機會更新這些動作的價值,進而讓最佳動作被選到。但是在貪婪法的遊戲規則內,沒辦法增加其他動作被選擇的可能性。因此數學家的作法,是讓我們有機會不採用貪婪法的決定。
在 - greedy 中, 代表的即是不採用貪婪法的機率。透過這種方法,我們有機會更新更多的動作價值,流程如下:
主要差異在於 (c) 中,選擇 a* 的方法。原本的貪婪法中,完全由動作價值決定,但現在我們有 的機率會採取隨機的動作。整體看來,我們有
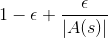 的機率,會採取貪婪法決定的動作。
的機率,會採取貪婪法決定的動作。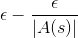 的機率,會採取其他動作,而各動作的機率為
的機率,會採取其他動作,而各動作的機率為 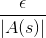 。
。其中 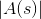 表示所有動作數量。下面使用 GridWorld 說明,設定如下:
表示所有動作數量。下面使用 GridWorld 說明,設定如下:
:0.3在狀態 2 的情況下,我們採取各動作的機率為
透過這種方式,可以增加其他動作被選到的可能性。
使用這種方法,很明顯的好處的增加選擇其他動作的機率,甚至找到比目前最佳動作更好的動作,在強化學習中稱這個過成為「探索 (exploration)」。然而,在我們真的找到最佳動作後,如果要獲得最大回饋的方法,反而要減少探索。
因此在設計上,通常會讓 隨著 episode 減少。也就是在一開始時有比較高的探索機率,看看能不能找到更好的動作;在進行與多次計算,對環境掌握的程度夠高後,就盡量按照找到的最佳動作運行。
在書中提到 - greedy 這個方法,現今強化學習中大多也使用這種方式。不過除了 - greedy 還是其他方法,可以增加選擇其他動作的機率。像是使用 softmax function,讓每個動作被選擇到機率由價值決定。
明天我們將實作使用 - greedy 的蒙地卡羅控制方法,如果讀者有興趣,可以嘗試將決定動作的貪婪法改成 softmax function,觀察會發生什麼事。


 iThome鐵人賽
iThome鐵人賽